


Porcupine by Picovoice
高精度かつ軽量なウェイクワードエンジンで知られている「Porcupine」、オフラインで動くようだし、完全オープンソースで知られている「Vosk」より、反応が速そうなので試してみました。
無料登録して、月1回ウェイクワードの登録ができるようです。
以下、その記録です。
Raspberry Pi 4B での操作
Raspberry Pi 4Bでは、SDカードに、Raspberry Pi OS Lite (64-bit) を入れて、USBにマイク、GPIOにスピーカーをつないでおります。
python3はインストールされているけど、pipはインストールされていなかったので、そのインストールも一緒に行っています。
// アップデートが可能なパッケージのリストを更新
sudo apt update
sudo apt install python3-pip
// pyAudioを使うため、PortAudio をソースからビルド
sudo apt install git autoconf libasound2-dev
git clone https://github.com/PortAudio/portaudio.git
cd portaudio
./configure
make
sudo make install
// その他の必要なものもインストール
sudo apt install libportaudio2 libportaudio-dev
sudo apt install python3-full python3-venv
// 仮想環境の設定
python3 -m venv ~/venv
source ~/venv/bin/activate
pip install pyaudio
// マイクのレートが違う場合に必要
pip install numpy
pip install scipy
PortAudio ライブラリパスをOSに通す必要があるので、仮想環境の「~/venv/bin/activate」を編集して、ファイルの末尾に以下を追加。
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH続いて、Picovoice サイトに移動します。
Picovoice サイトで新規登録&「Wake Word」作成
「Picovoice」にアクセスして、アカウントを作成します。
下にスクロールして、「Create Wake Word」をクリック。
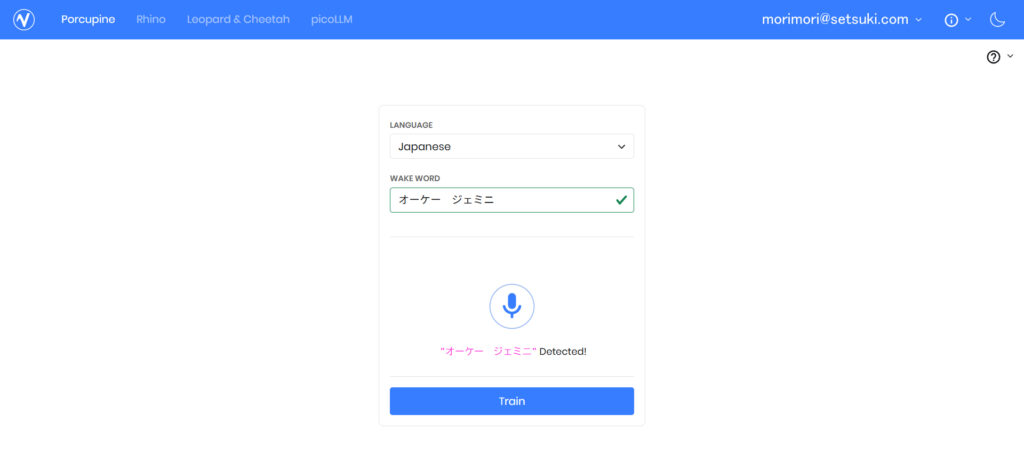
「LANGUAGE」は「Japanese」を選択し、
「WAKE WORD」には、ひらがな、カタカナ、スペースを使って、好きなワードを入力。
マイクマークをクリックして、上手く動くか検証。
「Detected!」と出たら、成功しているので、「Train」をクリック。
Pratformは、Raspberry piを選択して、ダウンロードして、zipの中のppnファイルをRaspberry piに入れる。
LANGUAGEを日本語にしたため、日本語モデルをダウンロード。
wget https://github.com/Picovoice/porcupine/raw/refs/heads/master/lib/common/porcupine_params_ja.pv
Pythonファイルの作成
以下の内容のPythonファイル(test.py)を作成。ちなみに、使用しているUSBマイクが、44100Hz固定のため、変換処理を行っています。
import struct
import pyaudio
import pvporcupine
import numpy as np
import scipy.signal
# porcupineの生成
access_key = "<AccessKey>" # アクセスキー
keyword_paths = ["/home/~/~.ppn"] # ← ダウンロードした .ppn ファイルのパス
porcupine = pvporcupine.create(
access_key=access_key,
keyword_paths=keyword_paths,
model_path="/home/~/porcupine_params_ja.pv" # ダウンロードした日本語モデルのパス
)
# オーディオストリームの生成
pa = pyaudio.PyAudio()
# マイクが対応しているレート(例: 44100Hz)で録音
mic_rate = 44100
mic_frame_length = int(porcupine.frame_length * mic_rate / porcupine.sample_rate)
audio_stream = pa.open(
#rate=porcupine.sample_rate,
rate=mic_rate,
channels=1,
format=pyaudio.paInt16,
input=True,
#input_device_index=1, # ← USBマイクのインデックス
#frames_per_buffer=porcupine.frame_length
frames_per_buffer=mic_frame_length
)
print("ウェイクワード検出を開始します...")
try:
while True:
# 録音(44100Hz)
pcm_bytes = audio_stream.read(mic_frame_length, exception_on_overflow=False)
pcm = np.frombuffer(pcm_bytes, dtype=np.int16)
# ダウンサンプリング(→16000Hz)
pcm_downsampled = scipy.signal.resample(pcm, porcupine.frame_length)
pcm_downsampled = pcm_downsampled.astype(np.int16)
# Porcupine に渡す
result = porcupine.process(pcm_downsampled)
if result >= 0:
print("ウェイクワード検出!")
except KeyboardInterrupt:
print("終了します")
finally:
audio_stream.stop_stream()
audio_stream.close()
pa.terminate()
porcupine.delete()
以下のコードで上手く動いたら成功!
python3 test.pyRaspberry pi 4B では、確かに高速に反応してくれて、いい感じです。
仮想環境の操作(覚え書き)
いつのまにやら、pythonを使う場合に仮想環境が必要になったので、以下の2つのコマンドを覚えておくと良さそうです。
//仮想環境終了
deactivate
//仮想環境開始
source ~/venv/bin/activate

コメント